[Customer quote placeholder. 2 to 3 sentences from a billing director or operations leader at a municipal utility, MSO, or property management company. Focus on time saved per cycle or exception backlog reduction.]

Most platforms treat issues as undifferentiated tickets in a generic queue. Critical incidents sit alongside minor ones, and the recurring patterns that drain support capacity never get visible. MultiBilling rebuilds Incident Management as an ITIL-aligned lifecycle that categorizes every issue by business impact, routes the ones that matter to the right owner, and turns recurring incidents into pattern insights that prevent them from returning. Customer service restores faster. Operations sees the underlying problems that cause repeat work. Customer service and operations teams reclaim more than half of their monthly labor for higher-value work.

Every issue gets categorized by business impact and routed to the right owner. The generic-ticket queue that used to bury critical issues alongside minor ones is replaced by a structured lifecycle for intake, prioritization, assignment, tracking, resolution, and closure. Service-affecting issues escalate automatically. Lower-priority work follows its own track without competing for attention. Customer-reported problems, service-related work, and product feedback each follow the right workflow from the start instead of getting jumbled together.
Account, billing, workflow, and prior-incident history surface inside the record. The team restoring service starts with the picture they need instead of hunting across screens. Affected customer, account, location, service, meter, bill, payment, user, workflow, screenshots, and supporting documentation arrive together. The AI Assistant summarizes the history, interprets related data, and recommends investigation steps. Triage that used to take an hour of context-gathering now starts with the context already gathered.

Patterns across incidents surface automatically. The underlying problems that cause repeat tickets get exposed so teams fix root causes instead of working the same issue repeatedly. Recurring categories, common workflows, and frequent customer segments emerge from the data. Leaders use the trends to reduce repeat issues, improve training, refine workflows, enhance knowledge articles, and strengthen the overall service model. Continuous improvement becomes a built-in discipline instead of a quarterly meeting.

Step 01
Conventional platforms log issues as undifferentiated tickets. The intake form captures a short description, the system assigns a queue, and the team works it in arrival order. Critical issues compete for attention with minor ones. Recurring problems remain invisible because nobody categorizes them consistently enough to count. MultiBilling rebuilds Incident Management as an ITIL-aligned lifecycle that classifies severity, routes by responsibility, and turns recurring tickets into pattern insights. Before, every issue looked the same in the queue. After, the lifecycle and the data surface what matters and where the underlying work needs to happen.

Step 02
Customer service restores service faster because the context arrives with the incident. Operations sees the patterns instead of repeating the work. Managers monitor incident aging, response time, resolution time, backlog, reassignment patterns, and recurring categories without compiling reports. High-impact incidents escalate automatically. Resolution history preserves the audit trail for compliance and continuous improvement. Across customer service and operations, the time lost to context-gathering, repeat tickets, and reactive firefighting drops sharply, and staff reclaim more than half of the customer service and operations team’s monthly labor for higher-value work.

Step 03
Incident Management connects to CIS for customer and account context, to billing for transaction history, to service requests for related work, to reporting for service-level visibility, and to the AI Assistant for guided investigation. Event-based monitoring triggers notifications when incidents remain unresolved, breach response windows, or relate to recurring patterns. Escalation rules respond to business impact. Knowledge content and procedures surface inside the workflow. Resolution data feeds continuous improvement loops. The result is incident management as a connected, observable, AI-ready discipline.

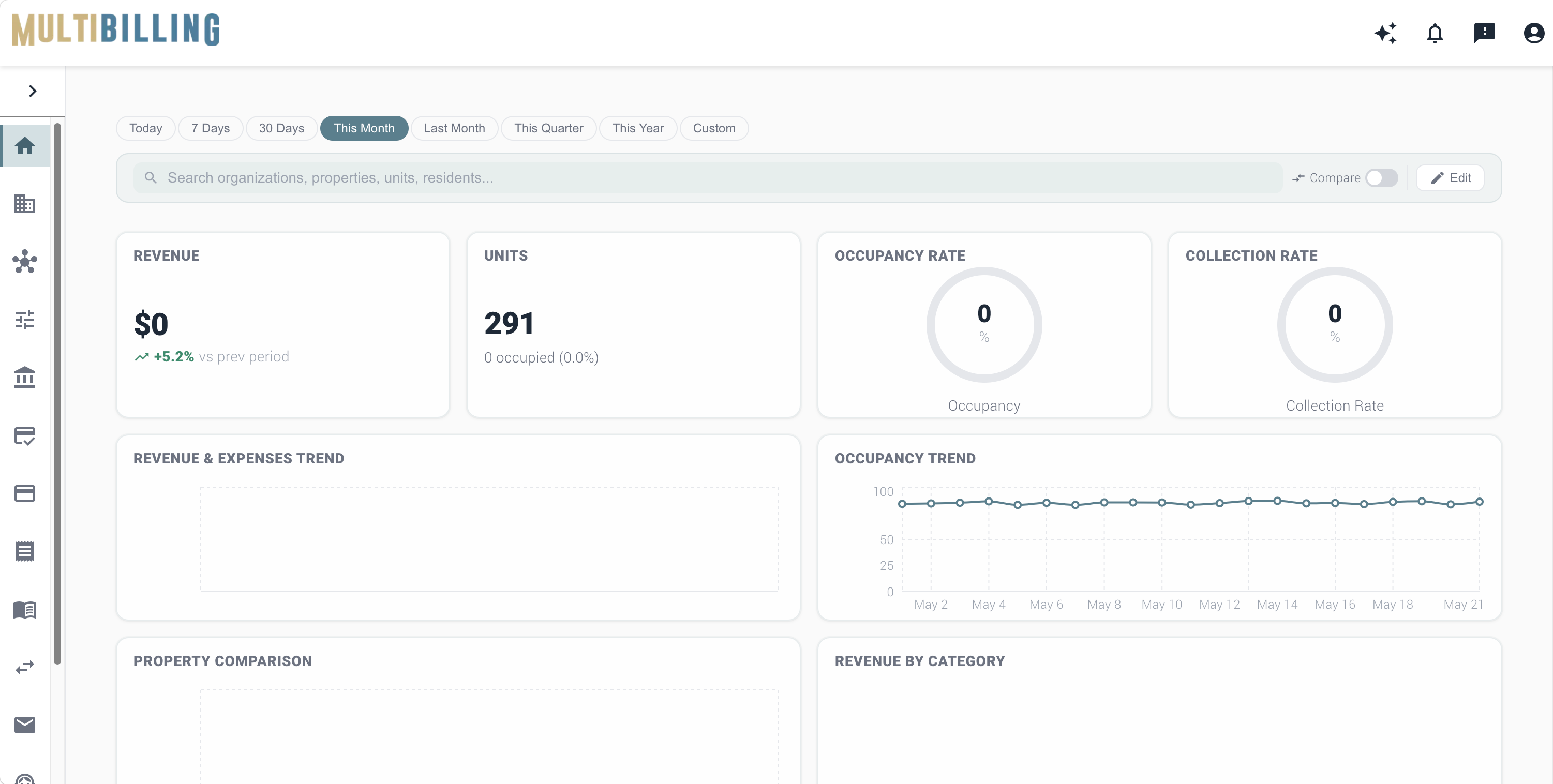
[Customer quote placeholder. 2 to 3 sentences from a billing director or operations leader at a municipal utility, MSO, or property management company. Focus on time saved per cycle or exception backlog reduction.]
Trusted by Utility & Property Operations Teams





Send us a sample of the incidents your team handled last month, and we will show you the same volume inside MultiBilling. You will see the routing, the context, and the pattern analysis on real data. The day your team stops reworking the same ticket is the day the labor reclaim starts.
Schedule a demo to explore the platform in detail and see how MultiBilling fits your operations and take the next step toward implementation and purchase.
.png?width=1448&height=1086&name=Futuristic%20Screenshot%20of%20MultiBilling%20(1).png)